
Disclaimer
This article is intended to be an introduction to machine learning applied to cybersecurity that is understandable even to those who approach it without a prior knowledge of the subject.
In order to show weaknesses not all best practices will be followed and some logical errors will be voluntarily included, including code. Therefore, the invitation is to read, learn more about the topic without blindly replicating the vulnerable code or practices.
This little research aims through the invention of a likely but simplified scenario to show how machine learning can assist cybersecurity. It is not a comprehensive guide or a step by step tutorial but an introduction to an advanced topic. The idea to write a few words on the topic stems from the lack of beginner-friendly practical examples available to anyone who would like to try to approach the topic.
All resources used to follow are open source, and the code used will be reported and commented on as we go along to allow the reader to try it out for themselves.
Any reference to actual events and/or real people is to be considered purely coincidental.
The Scenario
One day a bank named TriDebit hears about a new technology that is permeating every industry called Artificial Intelligence (AI) and decides to start a project to detect and block the most popular attacks on its web applications. Within TriDebit, however, there is no team specializing in this field, so they decide to inquire and analyze the problem of getting the project off the ground.
The history of artificial intelligence begins in 1955, a time when the term was first used even though earlier work aimed at a ‘learning machine’ had already been developed. Seventy years have passed since then, and the concept of artificial intelligence has expanded and specialized in different branches thanks to the work of researchers, universities and companies that have pursued the research.
The most famous fields nowadays are:
- Machine Learning (ML): This is the core of AI, where machines learn from data to make decisions or predictions.
- Deep Learning (DL): A subset of machine learning, deep learning uses neural networks with many layers (hence “deep”) to analyze various factors in large volumes of data. It’s the technology behind many advanced AI functions, such as speech recognition, image recognition, and natural language processing.
- Natural Language Processing (NLP): This field focuses on the interaction between computers and human languages. It involves the development of algorithms that can understand, interpret, and respond to human languages.
- Computer Vision: This field enables machines to interpret and process visual data from the world, similar to human vision. It has applications in image recognition, video analysis, and autonomous vehicles.
There are many additional branches and each of them contains within it techniques and more precise subdivisions to address each field accurately. But this is outside the scope of this research.
For TriDebit, in fact, it is enough to be able to replicate a fairly simple cognitive process: receive, understand, identify, and decide. What the above descriptions suggest a Machine Learning model can do. Their project – and our research – can be described using the following schema:
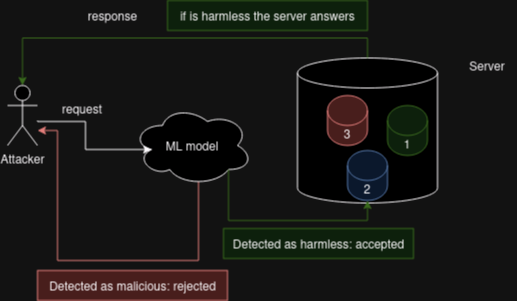
The model is used to identify and accept or reject incoming requests by analyze them as threats or harmless objects.
Machine Learning
Machine learning is a subset of AI that provides systems the ability to automatically learn from experience without being explicitly programmed with fixed set of rules.
The learning process begins with observations or data, such as examples, in order to look for patterns in data and make better decisions in the future based on the examples that we provide. The primary aim is to allow the computers to learn automatically, even without human intervention or assistance and adjust actions accordingly.
There are several types of machine learning methods:
- Supervised Learning: The algorithm is trained on a pre-defined set of training examples, which then facilitate its ability to reach an accurate conclusion when given new data.
- Unsupervised Learning: The algorithm is used when the information used to train is neither classified nor labelled. Unsupervised learning studies how systems can infer a function to describe a hidden structure from unlabelled data.
- Semi-supervised Learning: Falls between supervised and unsupervised learning, where the system uses both labelled and unlabelled data for training a small amount of labelled data and a large amount of unlabelled data.
- Reinforcement Learning: A method of machine learning where an agent learns to behave in an environment by performing actions and seeing the results of these actions.
TriDebit has many logs of attempted attacks suffered previously, so it decides to proceed with a supervised learning model.
Supervised learning has many advantages, such as clarity of data and ease of training. In fact, in this hypothetical case there is the possibility of selecting and using a large dataset. In particular, it is decided to start the project from a well-known attack: SQL Injection.
To mimic this invented labelled logs an open source dataset from Kaggle will be used. This dataset contains different CSV that was modified and joined to create a new one called bigger.txt in code snippets.
https://www.kaggle.com/datasets/syedsaqlainhussain/sql-injection-dataset
Algorithm selection
Analyzing the problem to extract the requirements from it shows that:
- Given a generic input I there is a need to understand whether that input is malicious and should be discarded or otherwise accepted. It is therefore a binary output (0,1).
- The available data are already divided into malicious and safe. They are said to possess a label. Training takes place on this data.
- There is no possibility of automatic learning through the new data that will be used when the model is used.
Having taken the requirements into consideration, a model based on ‘Logistic Regression’ is chosen, used for classification and not regression problems. Predicts the probability of a categorical outcome based on one or more predictor variables called features.
Logistic Regression
Logistic regression is a statistical model used for binary classification tasks. It estimates the probability of a binary outcome (like success/failure, yes/no) based on one or more predictor variables – features.
In mathematical terms, logistic regression models can be described by the logistic function. Logistic function is a sigmoid or an S shaped curve with the following equation:
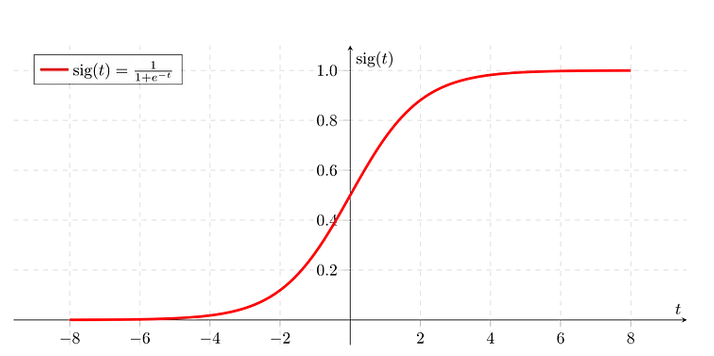
A little more mathematically, the function can be explained this way: the output of 1 divided by any non zero number is always kept between 1 and 0 – (0,1). The typical form is obtained by e base of the natural logarithm raised to t, where t is sum of the values of the individual coefficients for the respective features.
Thus, this model proves to be effective yet easy to understand and describe, promoting understanding of its hypothetical use in our hypothetical scenario.
Development
Dataset
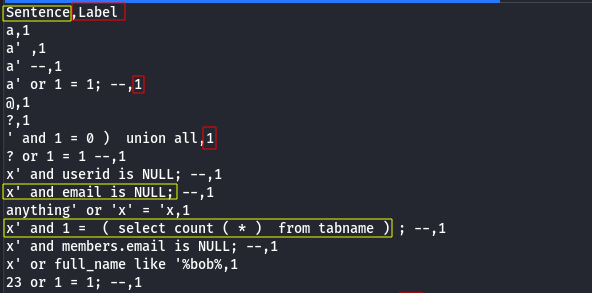
Dataset imported from a .CSV file can be computed using pandas and scikit-learn libraries in python3. There are two available columns in the dataset: Sentence and Label.
Sentences are the data, sql injection or harmless queries, and Label hold the boolean value to identify if the query is safe or not.

Training
This Python code shows the process of training the logistic regression model using the scikit-learn and pickle library to serialize and save it. The dataset is loaded from a .CSV file, features are defined (but so far not made public), then the data is divided into training and test sets.
The logistic regression model is trained with a maximum of 1,000 iterations, and the data is split into 80 percent for training and 20 percent for testing.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import pickle
# Load the dataset
file_path = 'bigger.csv'
dataset = pd.read_csv(file_path)
# Handling non-string or missing values in the 'Sentence' column
dataset['Sentence'] = dataset['Sentence'].astype(str)
# features
'''
REDACTED
'''
# load after the first two columns
# Training 80% - Test 20%
X=dataset[dataset.columns[2:]]
y=dataset['Label']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
print('Training..')
clf = LogisticRegression(max_iter=1000).fit(X_train, y_train)
# save the model to disk
print('Saving..')
pickle.dump(clf, open('finalized_model.sav', 'wb'), protocol=2)Testing and Performance
The following code is written to test the model against a new unknown query new_sentence. Code output will be 0 to identify harmless query and 1 for detected SQLi.
import pickle
import pandas as pd
# load the model and vectorizer from disk
clf = pickle.load(open('finalized_model.sav', 'rb'))
# test a new 'Sentence'
new_sentence = "Is this wzoq7ft9qlrs00d6v80v~ = /* !!" # example
# Create additional features
'''
REDACTED
'''
# dictionary population example
d = { 'RND_FEATURE_1': [FEATURE_VAR_1], 'RND_FEATURE_2': [FEATURE_VAR_1]}
# dataframe creation from dictionary
features = pd.DataFrame(data=d)
# predict the label
predicted_label = clf.predict(features)
print("Predicted Label:", predicted_label[0])
The model seems effective in correctly identifying malicious and harmless cases as showed in the following image.

Fraudolent Accuracy
The model has 96% of accuracy, a good number, the company should be proud. But it is important to keep in mind in all data analysis, not just in the ML environment that metrics need to be put into context and pitfalls taken into account.
In particular a model could achieve high Accuracy by predicting the majority class most of the time. For example a model can detect every harmless query correctly and only few as harmful and still have decent Accuracy.
For this reason another metric was reported: Precision. Precision is a helpful metric when you want to minimize False Positives. In our scenario this metric is really important because discard legitimate request can lead to a revenue loss for the bank. At this point a careful reader should ask why the model cannot have high precision and include every actual positive? This metric is called Recall. Recall is a helpful metric when you want to minimize False Negatives.
Empiric studies discovered a rule that cannot be subverted: Precision and Recall are a tradeoff. When one raise the other decrease. This simple statement is a key concept in ML and data analysis and it could be deepened in future writings.
Features
TriDebit Bank made a mistake within its development process. Specifically, as could be seen from the previous paragraphs, features were omitted and a portion of the dataset analysis was not presented.
In this case the error is the lack of thorough analysis of the available data and its quality. In fact, 17 hand-picked features typical of the SQL Injection vulnerability were selected agnostically to the dataset.
In particular, it was not verified that the features are not correlated in order not to create bias during the training phase and that the dataset covers a complete case pool.
The features are presented more fully in the code snippet to follow. One can observe almost all of them expressed as a Boolean value of factors types of SQL Injection (keywords such as and or plus symbols such as comments -- #). For completeness of example, a continuous value variable in N such as string length was also included.
def check(sentence, characters):
return '1' if any(char in sentence for char in characters) else '0'
quotes = ["'", '"']
comments = ["--", "#"]
multiline = ["/*", "*/"]
symbols = [";", ","]
marks = ["?", "!"]
dataset['quote_present'] = dataset['Sentence'].apply(lambda x: check(x, quotes))
dataset['comments_present'] = dataset['Sentence'].apply(lambda x: check(x, comments))
dataset['multiline_present'] = dataset['Sentence'].apply(lambda x: check(x, multiline))
dataset['symbols_present'] = dataset['Sentence'].apply(lambda x: check(x, symbols))
dataset['marks_present'] = dataset['Sentence'].apply(lambda x: check(x, marks))
dataset['space'] = '1' if " " in dataset['Sentence'].any() else '0'
dataset['at'] = int("@" in dataset['Sentence'])
dataset['dollar'] = int("$" in dataset['Sentence'])
dataset['length'] = dataset['Sentence'].apply(len)
dataset['_or'] = int("or " in dataset['Sentence'])
dataset['_not'] = int("not " in dataset['Sentence'])
dataset['_and'] = int("and " in dataset['Sentence'])
dataset['_where'] = int("where " in dataset['Sentence'])
dataset['_select'] = int("select " in dataset['Sentence'])
dataset['_from'] = int("from " in dataset['Sentence'])
dataset['pipe'] = int("|" in dataset['Sentence'])
dataset['_union'] = int("union " in dataset['Sentence'])
dataset['equals'] = int("=" in dataset['Sentence'])
# example list for testing - not exaustive
quote_present = int(any(quote in new_sentence for quote in ["'", '"']))
comments_present = int(any(quote in new_sentence for quote in ["--", "#"]))
multiline_present = int(any(quote in new_sentence for quote in ["/*", "*/"]))
symbols_present = int(any(quote in new_sentence for quote in [";", ","]))
space = int(" " in new_sentence)
marks_presence = int(any(quote in new_sentence for quote in ["!", "?"]))
at = int("@" in new_sentence)
dollar = int("$" in new_sentence)
length = len(new_sentence)
_or = int("or " in new_sentence)
_not = int("not " in new_sentence)
_and = int("and " in new_sentence)
_where = int("where " in new_sentence)
_select = int("select " in new_sentence)
_from = int("from " in new_sentence)
pipe = int("|" in new_sentence)
_union = int("union " in new_sentence)
equals = int("=" in new_sentence)As can be seen from the above code the features were selected knowing the scope. Although knowing the research subject matter is a favourable factor it’s not by itself sufficient to guarantee a valid result, although the numbers seem to show otherwise. This will be especially useful to attackers.
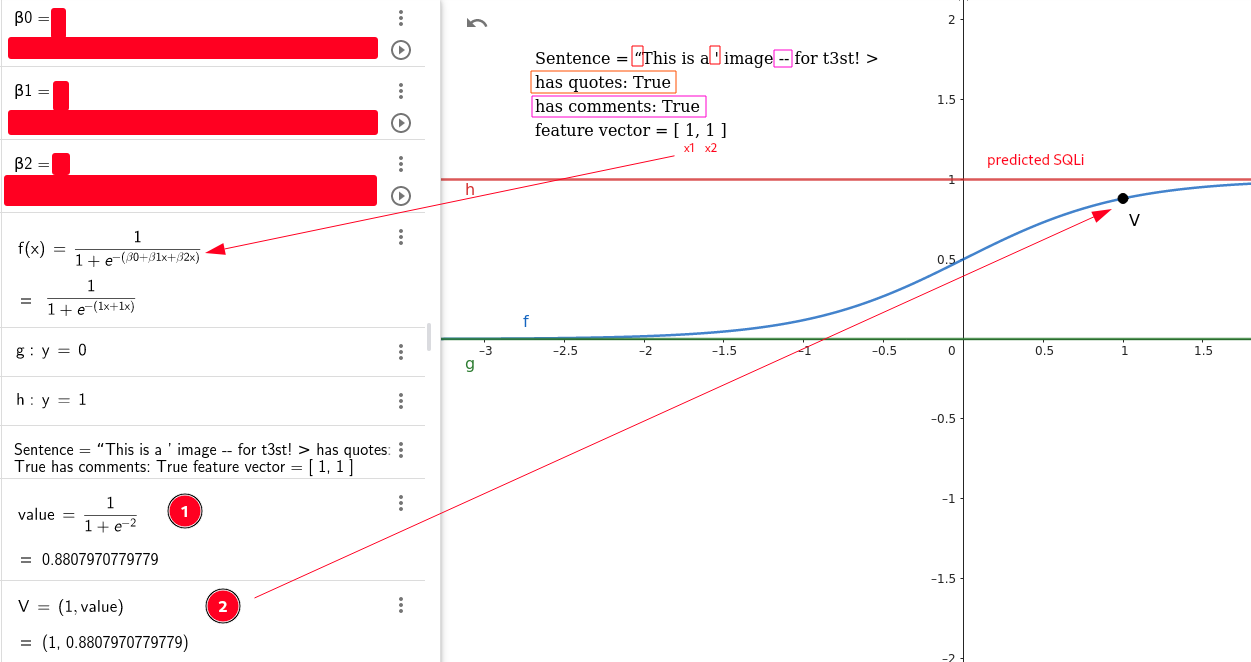
Because in this writing math is, ahimè, overlooked a visualization is offered as example in the hope of making a welcomed effort.
Be careful that coefficients beta_n are dummy values and only two boolean feature where used. But, as previously stated, continuos values are admitted and encouraged. In particular x_n refers to x_1 and x_2 for the final result V.
Offensive Analysis
The Scr1ptK1ddi1Op5 groups discovered that TriDebit bank is using a brand new technology to pretect their endpoints. From Open Source Intelligence they gathered the information that a new team was assembled to work internally on Machine Learning algorithm. Using this information the cyber-group understood that the a ML model was created to prevent attacks.
From Scr1ptK1ddi1Op5 point of view this is a black-box situation because they don’t know anything about the victim’s model, for example algorithm, selected features.
From further enumeration Scr1ptK1ddi1Op5 group noticed that a lot of their payload were rejected without showing the response so they studied the possible attacks. Usually ML attacks generally aim to manipulate the model’s predictions or to glean sensitive information from it. The most common types of attacks include:
- Adversarial Attacks: The attacker creates malicious input data that is specifically designed to cause the model to make a mistake. In the context of logistic regression, this could mean crafting input features that appear normal but are actually engineered to cause the model to output an incorrect prediction.
- Data Poisoning Attacks: This type of attack occurs during the training phase or during later automatic learning/adjusting. The attacker injects malicious data into the training set, which can skew the model’s learning process, leading to biased or incorrect predictions.
- Evasion Attacks: Closely related to adversarial attacks, evasion attacks happen at the time of prediction. The malicious actor modifies the input data to evade detection or produce a desired outcome without necessarily having the model make an incorrect prediction.
- Model Extraction Attacks: The attacker aims to create a copy or approximation of the machine learning model by using its predictions. Using a clone or a close copy of a machine learning model attackers can improve their attacks by creating more precise evasion payloads.
- Membership Inference Attacks: These attacks are designed to determine whether a particular data point was part of the training dataset. This can be a concern about data confidentiality, especially if the training data contains sensitive information.
From the above listener a careful reader will understand that in our example at the least one of the attacks is not feasible. Data Poisoning attack cannot be performed because the model was trained using supervised learning. It’s input were labelled from trusted source and after the training phase the model is frozen, it is impossible perform data pollution on the training set.
Model Extraction Attack
Model Extraction Attack is a stealing technique. It’s aim is to replicate a machine learning model. In particular the attacker’s goal is to create a model that closely approximates or duplicates the functionality of the victim model. In these attacks, the adversary queries the target model with various inputs and observes the outputs. By doing this extensively, they gather enough data to train a new model that mimics the behavior of the original model. This is feasible even with the black-box situation – like our scenario.
One the most common situation occurs when the victim model itself is a source of training for the attacker. We built our example like that. In our fake scenario the Tridebit model has a boolean output and two distinct behaviours based on the classification output. The attacking group can abuse this functionality to observe which output produce a specific classification. This flaw alone is not enough to extract successfully information to create a copy of the victim model as the attackers do not know which features are evaluated.
Exploitation
Model Extraction can be summarized in key steps:
1) Objective: The primary goal is to create a new model (the “extracted model”) that performs similarly to the target model on the same tasks, without having direct access to the target model’s architecture, parameters, or training data. Typically, these attacks assume black-box access.
The first step was already defined in the above paragraph by the Scr1ptK1ddi1Op5 gang.
2) Data Collection: The attacker queries the target model with a set of inputs and collects the corresponding outputs. This dataset of input-output pairs forms the training data for the extracted model.
The main goal in this part is to obtain a dataset from the victim model. Attackers usually needs to perform a lot of queries to create complete random dataset to cover the maximum numbers of case. This task can be achieved in our scenario by sending a lot of request with strings composed by random chars of random length.
A little improvement can be done by focusing on which strings are triggering the rejection because they contain features that are contributing in the logit function.
As example a snippet of code is attached. In particular random strings are created and mutated every generation based on the boolean feedback of the victim model. You can imagine it as a very basic genetic algorithm. This trick is useful to reduce remote queries space.
Note: genetic algorithms are a completely different field and deserve ad hoc writings so they will not be explained here.
import random
import string
import pickle
import pandas as pd
clf = pickle.load(open('finalized_model.sav', 'rb'))
# little parameters used for showcasing
GEN_NUMBER = 10
MAX_WORDS = 5
OBJ_PER_GEN = 10
def feedback_sample(new_sentence):
# remote model emulation model
'''
SAME CODE USED IN THE PREVIOUS SECTION
'''
return clf.predict(features)
def generate_random_string():
words = ["".join(random.choices(string.printable[:-4], k=random.randint(1, 5)))
for _ in range(random.randint(MAX_WORDS // 2, MAX_WORDS + 1))]
return ' '.join(words)
def mutate_string(input_string):
words = input_string.split()
mutated_words = [mutate_word(word) for word in words]
return ' '.join(mutated_words)
def mutate_word(word):
if random.random() <= 0.5:
char_index = random.randint(0, len(word) - 1)
word = word[:char_index] + \
random.choice(string.printable[:-4]) + \
word[char_index + 1:]
return word
def genetic_algorithm(generations, population_size):
population = [generate_random_string() for _ in range(population_size)]
for generation in range(generations):
feedbacks = []
print(f"[!] *********** Generation {generation + 1}:")
for individual in population:
f = feedback_sample(individual)
print(individual, f) # local print to visualize output
feedbacks.append(f)
selected = [population[i] for i in range(len(population)) if feedbacks[i] ]
# crossing-over: not implemented but part of the stocastic genetic flow
# cut to go straight to the point
population = [mutate_string(individual) for individual in selected] + [generate_random_string() for _ in range(population_size - len(selected))]
genetic_algorithm(GEN_NUMBER, OBJ_PER_GEN)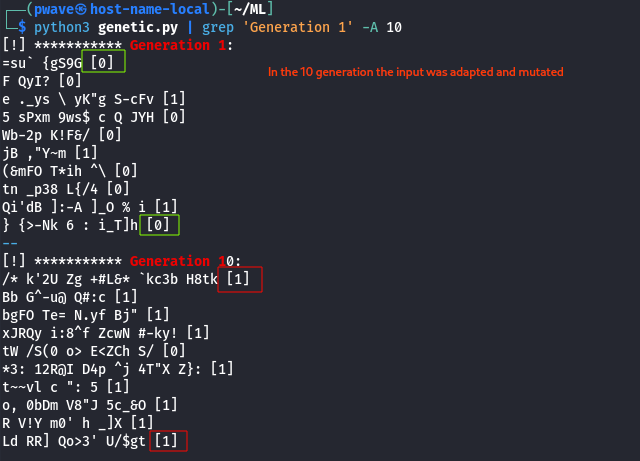
Analyzing the changes required for each generation to be flagged as malicious reveals the constant presence of certain characters: ' " #.
This technique also can be refined by introducing specific repeated or sequential characters using n-grams (“a collection of n successive items in a text document”).
Otherwise in the opposite way to the previous consider a malicious string and eliminate characters or n-grams from it until it is perceived as harmless.
From this analysis the relevant patterns that the Scr1ptK1ddi1Op5 was able to recover were: ' " -- || # //.
3) Model Training: Using this collected data, the attacker then trains a new model. The aim is to train this model to mimic the behavior of the target model as closely as possible.
This part is very similar to ‘Training and Testing’ part presented above but with a different dataset and feature vector.
The previous indentified chars will become the features for the clone ML model.
4) Evaluation: The success of the attack is evaluated based on how well the extracted model performs compared to the target model.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, precision_score
file_path = 'bigger.csv' # replace with your CSV
dataset = pd.read_csv(file_path)
dataset['Sentence'] = dataset['Sentence'].astype(str) # handle non-string values
dataset['Sentence'] = dataset['Sentence'].str.lower()
# discovered feature - cut for brevity
dataset['single_quote'] = int("'" in dataset['Sentence'])
dataset['double_quote'] = int('"' in dataset['Sentence'])
dataset['double_pipe'] = int('||' in dataset['Sentence'])
dataset['dot-comma'] = int(';' in dataset['Sentence'])
# recognized as comments
dataset['comments_present'] = dataset['Sentence'].apply(lambda x: '1' if any(quote in x for quote in ["--", "#", "//"]) else '0')
atk_x=dataset[dataset.columns[2:]]
atk_y=dataset['Label']
X_train, X_test, y_train, y_test = train_test_split(atk_x, atk_y, test_size=0.3)
print('Training Regression..')
clf = LogisticRegression().fit(X_train, y_train)
y_pred=clf.predict(X_test)
accuracy=accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, zero_division=1)
print("Accuracy & Precision:", accuracy, precision)From a research perspective to compare the data for us, it is possible to look at the metrics by comparing the data with the original model dataset. These results are improvable with the work done so far and it is left to the reader if he or she wants the work needed to raise the accuracy.
As expected the model the clone is not performing as good as the original one, but the precision is slightly better because only relevant feature was used – the original model selected them as you will see in the following lines.

In a real-world context, the attack team would have to use queries to the victim model to build the dataset. Again, knowing the scope could have improved the results, but for brevity we will pretend that the # -- // characters are not associated with comments. They are just perceived as sensitive symbols.
The attack was successfull.The actors were able to create copy that is able to mimic the original model. The new copy is different from the original one as you can see from feature list and identification phase. However this copy it is accurate enough to let the attacker study the model and what is being discarded to build a payload that bypass this naive defense.
If you want you can try to craft a payload by yourself.
The features were identified differently and not completely, although the confidence level of the cloned model seems high. This happens because the starting model, the TriDebit model (intentionally) had an incomplete dataset and no pre-analysis was done on the data.
Through sensitivity analysis, it is possible to understand which features contribute positively to the correct identification of the true positive. Specifically, only the first three features are actively used, while the others have correlations and do not contribute.
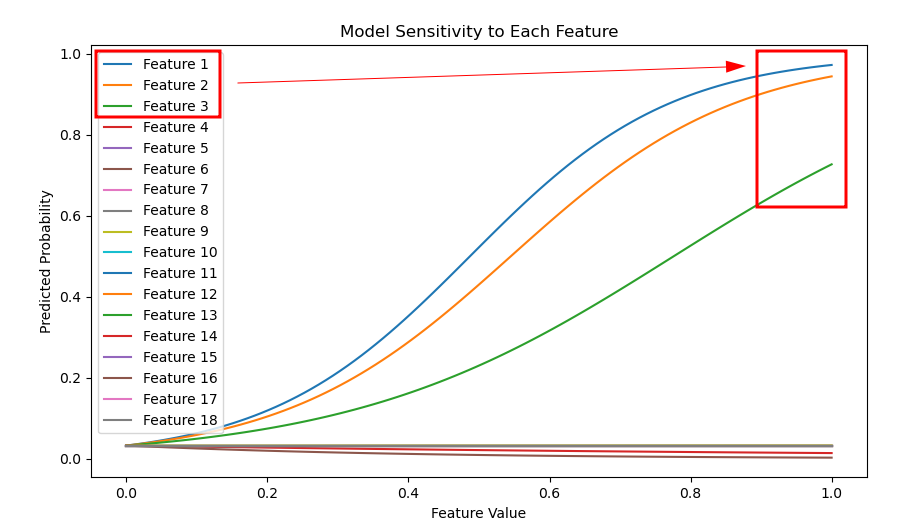
As you can see in this image not every feature is contributing to the model and only some of them are very relevant.
These characteristics are very similar to those that the attackers were able to discover and imitate.
If you were hoping to find an always valid and automatic method of attack, I am sorry but that was not the purpose of the reading. Observational skills in this case are the pivotal in order to guide the reader through a more comprehensible and above all replicable reading without high requirements.
Mitigation
Defending against Model Extraction Attacks involves making it harder for attackers to gain useful information from querying the model. Some mitigations are available as general best practices but the environment and design understanding are keys to prevent attacks.
Rate Limiting can limit the number of queries an individual (bot, human or third party software) can make. Without a good set of labelled data is not possible for the attackers to implement a reliable model to mimic the victim.
Introducing external uncertainty when costantly probed. If the model is subjected to a constant flow of requests from the same source, it is advisable to send responses externally that make the evaluation appear different from how it was evaluated internally, in our scenario by random labelling answers.
Ultimately follow a proper procedure of machine learning model development and design. First select, analyze and understand the data and datasets at hand. Perform preprocessing on that data to filter out noise and select features appropriate for the application context. Only then proceed with the training phase, which may include different steps, and finally analyze the results in a cyclic manner. These steps were partially or entirely deliberately skipped within this research and the mock scenario created both for brevity and to create a vulnerable context.
By developing through a proper procedure, analyzing the data and with more features the attack becomes more complicated and less accurate.
Code to perform web emulation
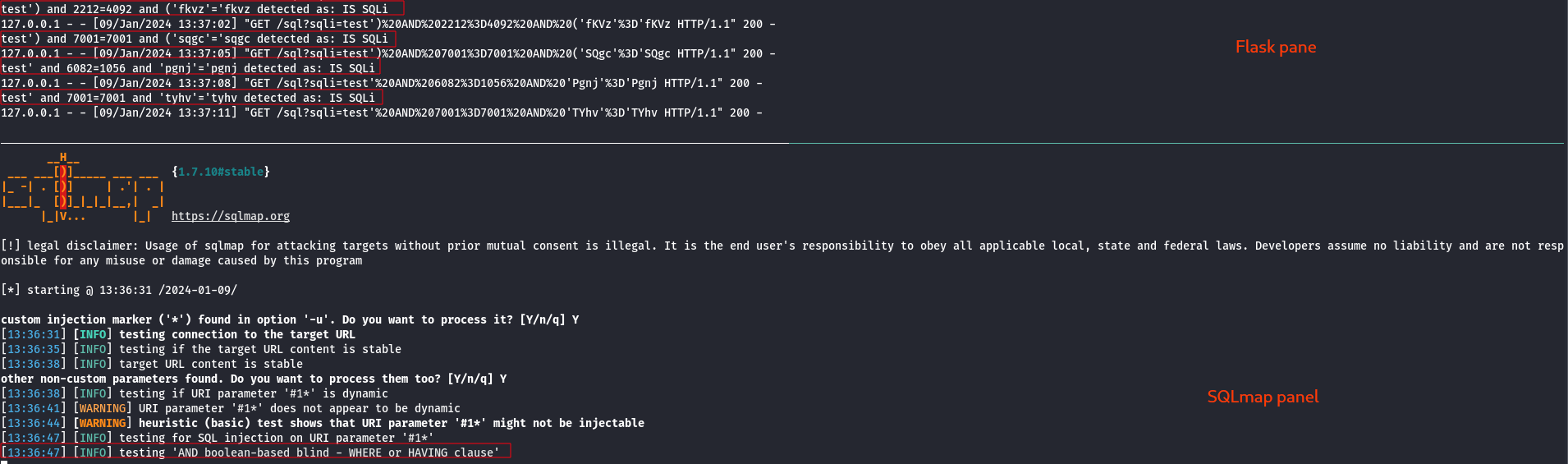
This section contains two code snippets one for flask and one template for testing locally what has been said so far. In particular the use of a web interface as middleware allows more convenient interfacing with tools, in the example given SQLmap dealing with sql injection.
Flask endpoint example:
import pickle
import pandas as pd
@app.route('/sql', methods = ['GET'])
def sqli():
new_sentence = request.args.get('sqli', default='', type=str)[0:256]
if new_sentence == '':
return render_template('sql-form.html', res='Empty string error')
else:
# if you load the model from pickle serialzie you won't need libraries
clf = pickle.load(open('[PATH]/[TO]/finalized_model.sav', 'rb'))
comments_present = int(any(quote in new_sentence for quote in ["--", "()", "#"]))
multiline_present = int(any(quote in new_sentence for quote in ["/*", "*/"]))
symbols_present = int(any(quote in new_sentence for quote in [";", ",", "|","]))
# ... your feature here
# ... and here
d = { 'comments_present': [comments_present],
'multiline_present': [multiline_present],
'symbols_present': [symbols_present]}
features = pd.DataFrame(data=d)
# Predict the label
predicted_label = clf.predict(features)
# Output the prediction
label = ''
if predicted_label[0] == 0:
label = 'NOT SQLi'
elif predicted_label[0] == 1:
label = 'IS SQLi'
return render_template('sql-form.html', res=label)Template example:
<!DOCTYPE html>
<html>
<head>
<title>SQL injection</title>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
</head>
<body>
<h1>Hello World!</h1>
<p>string <= 256 char. Boolean output.</p>
<br/>
<br/>
<p>{{ res }}</p>
</body>
</html>And this is the result (slightly modified for the sake of reading). Of course not every query will be detected as this writing explained because the dataset was not analyzed and cleaned and the feature not properly selected but this what did the attacker luck!
Machine learning and AI are not magic or a holy grail, but a an advanced and deep topic that must be understood or it will fail.
Ending
This can be just the first part of the TriDebit bank vs Scr1ptK1ddi1Op5 group conflict.
If it was entertaing and useful to learning new concepts let us know to (maybe) write a second part and how much deep delve in the rabbit hole.
Thanks for reading,
Riccardo Degli Esposti aka partywave
External resources
Additional insights and external resources of topics cut or over-simplified for brevity may be recommended:
https://towardsdatascience.com/precision-and-recall-88a3776c8007
https://ssg-research.github.io/mlsec/
https://web.stanford.edu/~jurafsky/slp3/5.pdf


Recent Comments